败犬日报 2024-11-29
败犬日报 2024-11-29
1. Linux 看程序执行了哪些系统调用
strace 一下。
2. std::string::clear 复杂度
https://zh.cppreference.com/w/cpp/string/basic_string/clear:
复杂度
与字符串的大小成线性,尽管既存实现在常数时间内操作。
没有要求是常数时间。
std::vector::clear 也同理。
3. 性能是怎么分析的
性能分析很复杂,这里也只讲了很有限的方法论。
一种是使用时间函数的性能测试。比如 benchmark,进一步可以在程序中间获取时间,从而得到详细的 profile 图。下图是 PyTorch 的 profile 图:

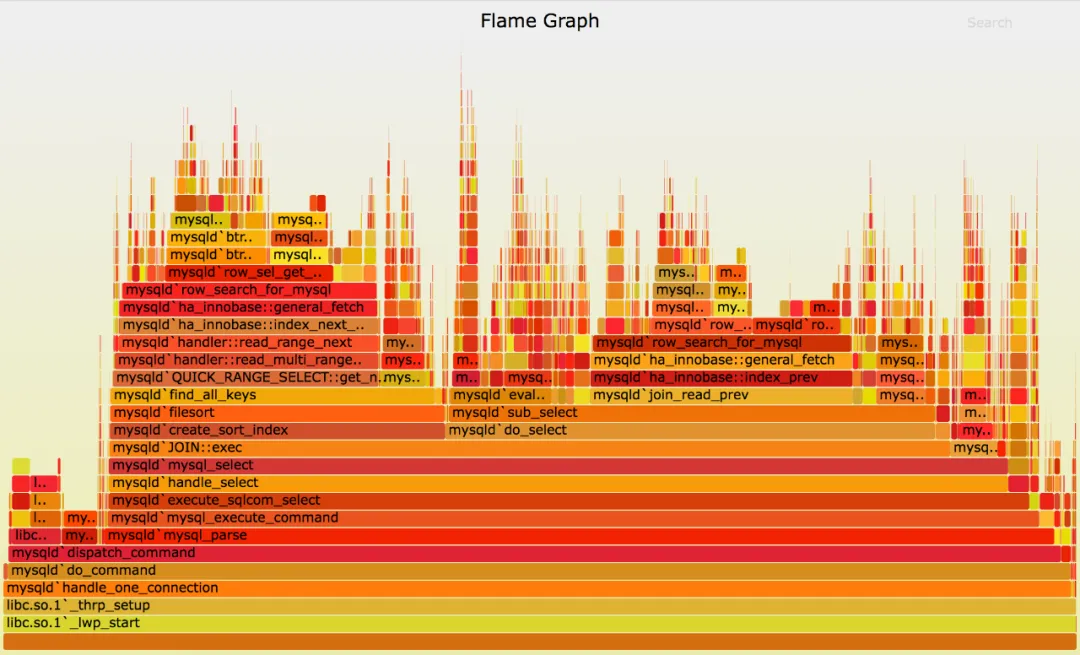
类似原理还有火焰图,以一个固定频率获取程序函数栈,就能知道什么函数耗时较长。
火焰图可以分 off cpu 和 on cpu。火焰图宽的地方很难知道具体原因,这个时候就需要 strace/eBPF 看具体的 syscall 怎么回事。
一种是 PMU 事件,通过硬件提供的 PMU 收集一些事件的计数,比如 cycle 数、指令数、cache miss、TLB Miss、分支预测失败、访存量、浮点运算次数等。进一步可以 topdown 分析。
sh
>>> perf stat ./main
Performance counter stats for './main':
55,374.68 msec task-clock:u # 14.748 CPUs utilized
0 context-switches:u # 0.000 /sec
0 cpu-migrations:u # 0.000 /sec
175 page-faults:u # 3.160 /sec
210,174,397,681 cycles:u # 3.795 GHz
59,993,767,241 instructions:u # 0.29 insn per cycle
7,776,746,070 branches:u # 140.439 M/sec
1,687,629 branch-misses:u # 0.02% of all branches
3.754660324 seconds time elapsed
55.360247000 seconds user
0.009982000 seconds sys应用层面是 red 原则 (request rate, error rate, duration) 和 use 原则 (usage, saturation, error)。
常见的工具包括 perf、gprof、valgrind、vtune(intel)、nsys/ncu(nvidia)、instruments(apple)。