败犬のC++每月精选 2024-11

败犬のC++每月精选 2024-11
本次精选了 14 个话题。
1. "pass-by-value and move"
构造函数或给成员赋值的函数,如果参数是 const T &arg 和 T &&arg,被称为 "pass-by-reference"。
cpp
struct Creature {
std::string m_name;
Creature(const std::string &name) : m_name{name} {}
Creature(std::string &&name) : m_name{name} {}
// 也可以使用完美转发,略
};如果参数是 T arg,被称为 "pass-by-value and move"。
cpp
struct Creature {
std::string m_name;
Creature(std::string name) : m_name{std::move(name)} {}
};"pass-by-value and move" 相比之下会多一次移动,但是写起来更简洁,适用于移动开销小的类型。
2. std::vector<bool> 的坑
因为 std::vector<bool> 是 vector 的特化,尝试通过位压缩来优化存储空间,8 个 bool 压成一个字节。
众所周知内存每个地址都是一字节,bool 数组的每个 bool 地址互不相同。但是 vector<bool> 一个字节是怎么区分 8 个地址呢?做不到。所以 std::vector<bool> 使用了代理对象(proxy object)让它使用上接近 vector。
比如访问元素 v[x] 会得到一个代理对象,而不是一个直接的 bool 引用。
cpp
#include <iostream>
#include <vector>
int main() {
std::vector<bool> vec = {false, false};
// bool& ref = vec[0]; // 编译错误:不能将代理对象赋值给 bool&
auto t = vec[0];
t = true; // 赋值会修改原数组
std::cout << static_cast<bool>(vec[0]) << "\n";
}当模板和 vector 结合时可能更难注意到这个坑:
cpp
template <typename T>
void f() {
std::vector<T> a(10);
T& x = a[0];
}
f<bool>();规避的话可以 std::vector<uint8_t> 或 std::vector<char> 实现相同功能。
标准委员会为了推销他们的特化,证明特化是多有用的一个特性的产物。结果就成了这样。
https://en.cppreference.com/w/cpp/container/vector_bool
目前编译器没有提供检查 vector<bool> 的功能。
https://reviews.llvm.org/D29118 有人做过,但是因为这个实现检查不了模板实例化时产生 vector<bool> 所以没合。
3. 性能比较 vec.emplace_back(x) 和 vec[x]
cpp
std::vector<double> result;
result.reserve(in.size());
size_t size = in.size();
for (size_t i = 0; i < size; i++) {
result.emplace_back(std::sqrt(in[i]));
}cpp
std::vector<double> result(in.size());
size_t size = in.size();
for (size_t i = 0; i < size; i++) {
result[i] = std::sqrt(in[i]);
}emplace_back 会检查并扩容。这个扩容行为是个复杂操作,导致编译器优化(比如向量化)比较困难。另一个角度是编译器没那么聪明。
vec[x] 没有检查就容易优化。
最容易让编译器优化的写法可能是:resize 后拿到 vec.data() 指针,直接操作指针。这样操作就不经过 vector 的成员函数。(群友表示经常这么干)
https://johnnysswlab.com/what-is-faster-vec-emplace_backx-or-vecx/
4. std::map 用 float 做为 key
浮点要考虑误差,map 用精确匹配可能找不到。
std::map 可以用 std::map::lower_bound 找 [key - eps, key + eps] 范围的数,类似这种方式进行模糊匹配。
最好不要重载比较运算符来实现模糊匹配,因为不能保证等于的传递性,a=b, b=c -> a=c。
5. 函数里的 lambda,lambda 里面定义了一个 static 变量,可以保证全局唯一吗
lambda 和函数类似,需要看类型签名,相同签名 lambda 内的 static 变量就是同一个,不同就不是。有没有捕获不影响结论。
cpp
#include <cstdio>
int main() {
auto f = [] (auto y) {
static int x = 0;
x++;
printf("%d", x);
};
f(1);
f(1);
f(1.0);
f(1.0);
}输出是 1212。
这里的 lambda 有两种签名(参数是 int 和 double),因此会有两个静态变量实例。
可以把代码塞给 https://cppinsights.io/ 看看 lambda 的行为。
6. 状态模板元编程 STMP
6.1. STMP 是什么
状态模板元编程,模板不再是个常量表达式。一个简单的例子是计数器,效果如下:
cpp
constexpr auto a = next();
constexpr auto b = next();
constexpr auto c = next();
static_assert(a == 0 && b == 1 && c == 2);6.2. 有用吗
看一乐就好,加深一下对模板的认识,不要真的写这样的代码。
这种代码十分依赖于模板实例化的位置,非常容易造成 ODR 违背,并且多次重复实例化会大大增长编译时间。
6.3. 阅读资料
6.4. 是缺陷吗
还没确定是缺陷,可能以后也不是。
已经在反射提案里提及。
cwg issue 和反射提案肯定要死一个,蹲结果就行。
6.5. 替代品
代码生成:用程序生成 C/C++ 代码,已有大量实践,如 protobuf。
静态反射:还需要等,未来可能进标准。
7. 败犬锐评 proxy
proxy 是这个库。
主要优化是胖指针,函数指针和对象指针放一起,不需要传统虚函数那样从对象上获取函数指针。
make proxy 如果表很小的话,直接存函数指针,而不是函数指针表,少一次间接寻址。
proxy 和虚函数比没什么特别的性能优势,只有非侵入式和侵入式的区别,没必要像一些网友那样捧上天。
8. 多态的性能
性能从高到低:编译期多态 > 运行期闭集 > 运行期开集
编译期多态,举例:模板、运算符重载和 CRTP。
运行期闭集,举例:std::variant。
运行期开集,举例:虚函数、函数指针。
9. 别名不会产生新的符号
看一下这个代码,报错是 error: pack expansion argument for non-pack parameter 'T0' of alias template 'template<class T0, class ... Ts> using Tint = int'。
cpp
template <typename T0, typename... Ts>
using Tint = int;
template <typename... Ts>
using A = Tint<Ts...>;由于 C++ 规定,别名(using)不能产生任何新的符号,所以在实例化之前就得全替换掉。但是包参数(typename... Ts)展开到非包参数(int)上就没法做这样的替换。
解决办法是套个 struct:
cpp
template <typename T0, typename... Ts>
struct Tint {
using type = int;
};
template <typename... Ts>
using A = Tint<Ts...>;模板的 name mangling 一个误解是 mangling 的类型是在整个模板替换完之后,把最终的类型给 mangling 了。但是实际上不是的。
https://godbolt.org/z/f46zKo31b 这里是直接 mangling 这个完全限定的特化类型。
10. 编译期笛卡尔积
比如 std::tuple A {m, n}, std::tuple A {o, p, q}, std::tuple A {x, y, z} 然后生成 std::tuple<std::tuple<m, o, x>, ...> 这个类型。
这个还是比较麻烦的,群友提供了实现 https://godbolt.org/z/en34P95cq。
11. unique_ptr 能不能看情况决定是否析构
unique_ptr 会存储 deleter(只是有时候会被空基类优化了)。
可以成员变量加个 bool,在 deleter 里进行判断;或者构造函数传入不同的 deleter。
cpp
#include <bits/stdc++.h>
struct A {
~A() { std::cout << "called ~A()\n"; }
};
struct Foo {
Foo()
: p(std::unique_ptr<A, void (*)(A *)>(
new A, +[](A *a) { delete a; })) {}
Foo(A *a) : p{std::unique_ptr<A, void (*)(A *)>(a, +[](A *a) {})} {}
std::unique_ptr<A, void (*)(A *)> p;
};
int main() {
Foo{};
A a;
Foo{&a};
std::cout << "===114514===\n";
}12. 无副作用的死循环是 UB(未定义行为)吗
cpp
#include <iostream>
int main() {
while (1)
;
}
void unreachable() {
std::cout << "Hello World!" << std::endl;
}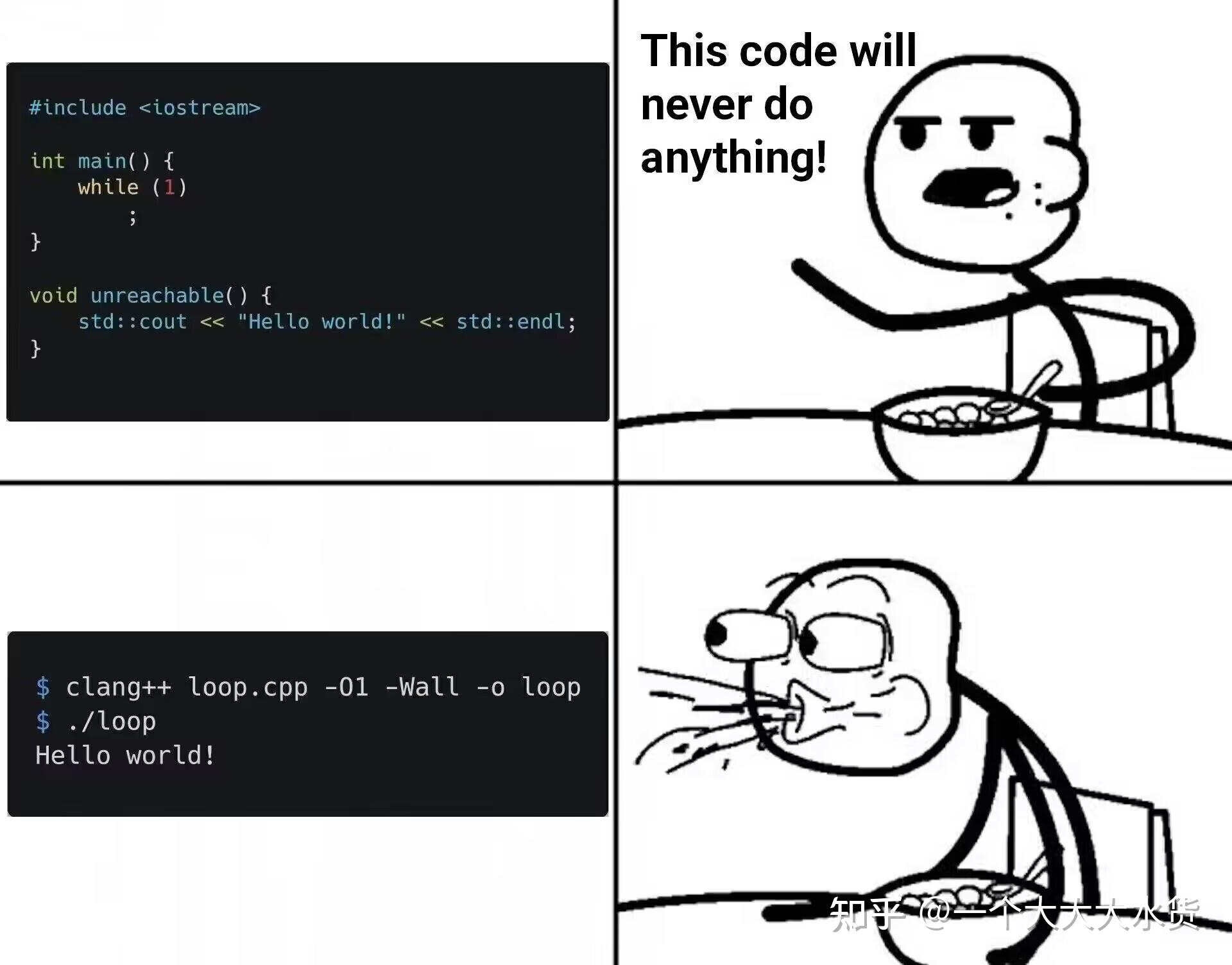
这是 clang 的一个 bug,clang 没给 main 生成一行代码,导致 main 函数地址和下面那个函数重叠了。现在已经修了。
那么无副作用的死循环是 UB 吗,这个之前一直有争议,p2809r0 已经确定不是 UB 了(更新:这个是不对的,p2809 只定义了平凡无副作用死循环,但是非平凡的还是 UB)。https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2023/p2809r0.html
13. 性能是怎么分析的
性能分析很复杂,这里也只讲了很有限的方法论。
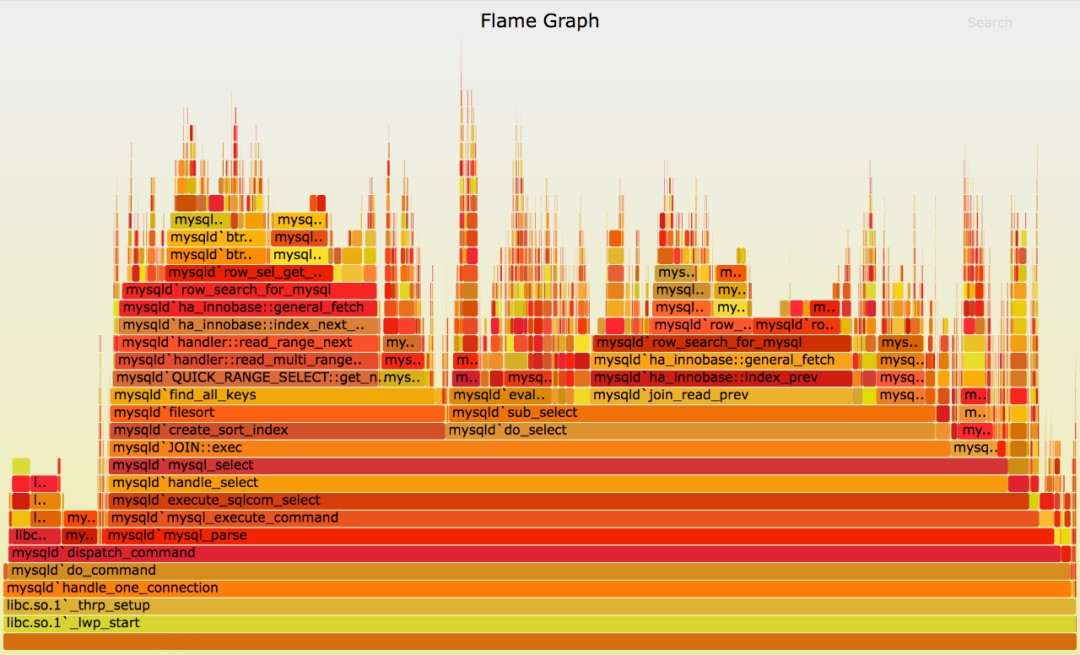
一种是使用时间函数的性能测试。比如 benchmark,进一步可以在程序中间获取时间,从而得到详细的 profile 图。下图是 PyTorch 的 profile 图:

类似原理还有火焰图,以一个固定频率获取程序函数栈,就能知道什么函数耗时较长。
火焰图可以分 off cpu 和 on cpu。火焰图宽的地方很难知道具体原因,这个时候就需要 strace/eBPF 看具体的 syscall 怎么回事。
一种是 PMU 事件,通过硬件提供的 PMU 收集一些事件的计数,比如 cycle 数、指令数、cache miss、TLB Miss、分支预测失败、访存量、浮点运算次数等。进一步可以 topdown 分析。
sh
>>> perf stat ./main
Performance counter stats for './main':
55,374.68 msec task-clock:u # 14.748 CPUs utilized
0 context-switches:u # 0.000 /sec
0 cpu-migrations:u # 0.000 /sec
175 page-faults:u # 3.160 /sec
210,174,397,681 cycles:u # 3.795 GHz
59,993,767,241 instructions:u # 0.29 insn per cycle
7,776,746,070 branches:u # 140.439 M/sec
1,687,629 branch-misses:u # 0.02% of all branches
3.754660324 seconds time elapsed
55.360247000 seconds user
0.009982000 seconds sys应用层面是 red 原则 (request rate, error rate, duration) 和 use 原则 (usage, saturation, error)。
常见的工具包括 perf、gprof、valgrind、vtune(intel)、nsys/ncu(nvidia)、instruments(apple)。
14. 有没有比 mt19937 更快的伪随机数算法
这里列举了亿些算法:https://www.pcg-random.org/
一个简单的例子就是 LCG(线性同余生成器),但是几乎没有安全性,只有快。
cpp
const long a = 1664525;
const long c = 1013904223;
const long m = 4294967296;
struct LCG {
long seed;
LCG(long s) : seed(s) {}
long next() {
seed = (a * seed + c) % m;
return seed;
}
};